Python: speed vs. memory tradeoff reading files
I was making a script to process some log file, and I basically wanted to go line by line, and act upon each line if some condition was met. For the task of reading files, I generally use readlines(), so my first try was:
f = open(filename,'r')
for line in f.readlines():
if condition:
do something
f.close()
However, I realized that as the size of the file read increased, the memory footprint of my script increased too, to the point of almost halting my computer when the size of the file was comparable to the available RAM (1GB).
Of course, Python hackers will frown at me, and say that I was doing something stupid… Probably so. I decided to try a different thing to reduce the memory usage, and did the following:
f = open(filename,'r')
for line in f:
if condition:
do something
f.close()
Both pieces of code look very similar, but pay a bit of attention and you’ll see the difference.
The problem with “f.readlines()” is that it reads the whole file and assigns lines to the elements of an (anonymous, in this case) array. Then, the for loops through the array, which is in memory. This leads to faster execution, because the file is read once and then forgotten, but requires more memory, because an array of the size of the file has to be created in the RAM.
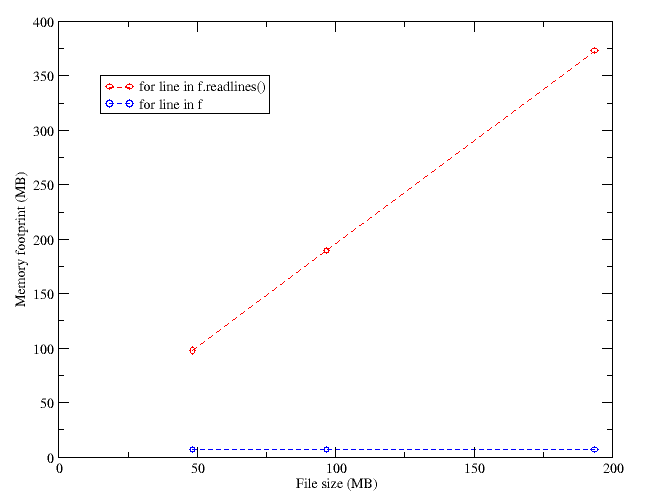
Fig. 1: Memory vs file size for both methods of reading the file
When you do “for line in f:“, you are effectively reading the lines one by one when you do each cycle of the loop. Hence, the memory use is effectively constant, and very low, albeit the disk is accessed more often, and this usually leads to slower execution of the code.

Fig. 2: Execution time vs file size for both methods of reading the file

paddy3118 said,
February 15, 2008 @ 11:40 am
Try looking at the memory mapping feature amongst others, mentioned here.
– Paddy.
isilanes said,
February 15, 2008 @ 14:26 pm
Nice reading! Thanks a lot for the link, Paddy.