Peer to peer: the new distribution paradigm
This post will hardly talk about rocket science, but there’s still a lot of ignorance on the subject.
A lot of people associate p2p with “piracy”, and eMule and BitTorrent with some shady way of obtaining the miraculous software of the big companies like Adobe or Microsoft.
Well, the fact is that p2p is a really advantageous way of sharing digital information through the net. Actually, the philosophy behind p2p is applicable to any process in which information, or some other good, is spread. So what is this philosophy? Simply put, p2p opposes a distributed way of obtaining t the goods, with a centralized one (see figure below).
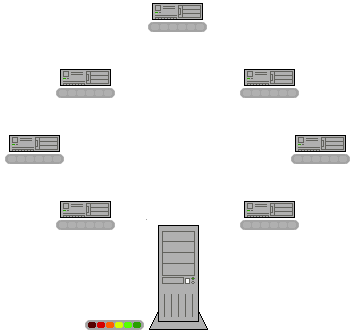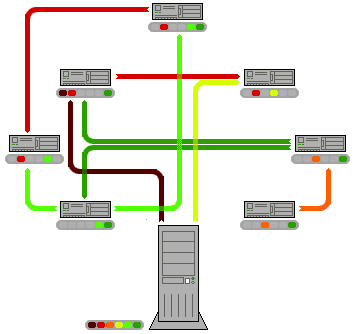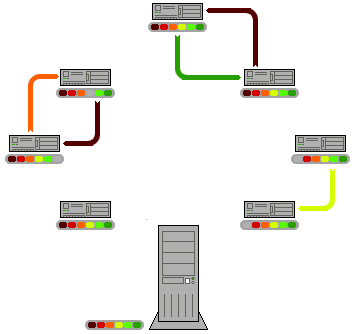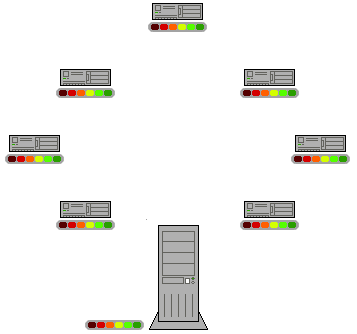
Figure 1: Scheme of operation of p2p network. From Wikipedia.
I use the BitTorrent p2p technology (with the KTorrent program) quite often, particularly to download Creative Commons music from Jamendo. Lately, I have used KTorrent to download some GNU/Linux CDs, particularly the 4.0 version of Debian, and the beta (and this weekend, the stable) version of Ubuntu Feisty Fawn. With the latter, I have come to feel more deeply the advantages of p2p over centralized distribution of files.
With a centralized way of downloading, there is an “official” computer (the server) that has the “original” version of the information to download, and all the people who want to get the info (the clients) have to connect to that server to get it. The result is quite previsible: if a given piece of software is highly sought, a lot of clients will flood the server, and it will not be able to provide all the clients with the info they request, slowing the transmission down, or even stopping it alltogether for further clients, once saturation is reached. This happened with the release of the Windows Vista beta, when the high demand of the program, and the low resources Microsoft devoted to serving the files, provoked a lot of angry users having to wait for unreasonable periods of time until being able to download it.
This problem could well happen with the release of Ubuntu Feisty Fawn, and in fact this morning connecting to the Ubuntu servers was hopeless. However, unlike Microsoft, Canonical decided to make use of the BitTorrent technology to serve the ISO files, and this made all the difference.
With a p2p way of serving the files, the first clients connect to the server to get the files. However, once they have downloaded a part of the files, they too become servers, and further clients can choose whether to download from the central server or from other clients/servers (usually the decision is taken automatically by the p2p program). As the net of clients grows, and the file flow is balanced, the download speed is maximized for all, and the load on the servers is kept within reasonable limits.
The advantages are clear: each person willing to download some files (e.g. the Ubuntu ISOs) does not become a leech, imposing a burden on the server, but rather a seeder, providing others with the files, and speeding up, not slowing down, the spread of the files. It is, thus the ideal way of distributing files.
However, it has two disadvantages that made Microsoft not use it to spread the Windows Vista beta: since there is no single server, controlled by a central authority, it is not possible to assert how many copies of the files have been distributed. Moreover, since the distribution net is scalable, it can not choke, and thus MS would not be able to claim that the demand for their product was so high that the servers were not able to attend it.
So, for promotional purposes, the p2p is not very good. If your priority is the client, and making the files as widely and quickly spread as possible, then p2p is for you.
