Project BHS
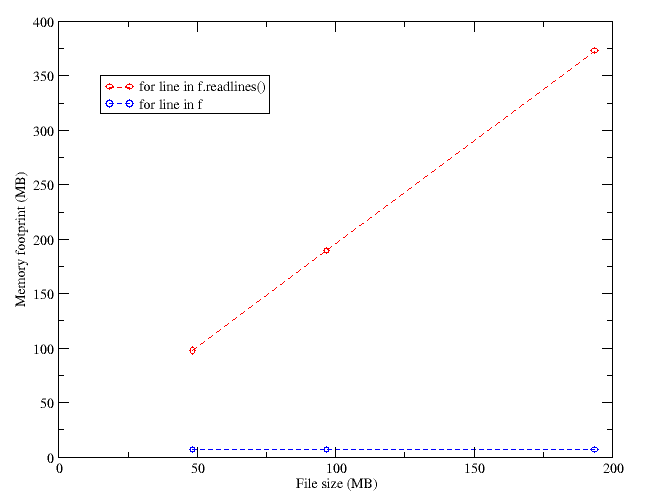
As outlined in some previous posts[1,2,3,4], I have been playing around with a piece of Python code to process some log files. The log files to process were actually host.gz files from some [[BOINC]] projects, and the data I want to extract from them is quite simple: the Windows, Linux and Mac shares in the number of computers contributing to them (and the [[BOINC Credit System|work they do]]). By logging this processed data myself, I can see the time evolution of this share, and hopefully show the slow but steady rise of GNU/Linux :^)
I figured out that the contribution to distributed computing projects could be a reasonable indicator of the Windows predominance status. There are many other indicators (for example the number of visits to a web site, e.g. this very one), and I don’t claim that this one is “better”. I just want to add it to the reference list for the reader.
There is a problem with “Windows vs. Linux” figures, and it is that they are not really “competing” products. When cars or soft drinks are the subject, one can figure out the [[market share]], looking at the number of items sold. Linux being [[free software]], one can hardly measure the amount of “sold copies”, and with Windows being pre-installed in most new computers, one can not really trust the “number of computers sold = number of Windows copies sold”, because some users even remove the Windows partition and install Linux on top of it.
Counting the visits to some sites is not without problems, either. Any web site will have a particular audience, and the result will be biased by that fact. When my blog was in WordPress.com, I had roughly as many visits from Windows users as from Linux users, and almost all of them used Firefox as a browser. Obviously this data is not an accurate reflection of the world at large. It so happened that free software users are more likely to surf to sites like mine, hence the bias.
So, without further ado, let me introduce the “BOINC Host Statistics” program (BHS). Here you are a link to its home page. You can find results I have harvested so far in the Screenshots section. For example, the SETI@home credit generation rate statistics follows:

What the plot tells us is that (at the time of writing this) 500 million [[BOINC Credit System|cobblestones]] are being granted to contributors each day. Of them, around 82% are being given to Windows computers, 9-10% to Mac, 8% to GNU/Linux, and the rest to computers running other OSs.